Python WebScrapper Introduction
5.1 Introduction
웹 스크래핑은 user가 쓴 코드가 웹사이트에 들어가서 데이터를 추출해내는 것이다.
indeed.com ( 구인구직 사이트 ) 에서 검색할 수 있는 모든 프로그래밍 관련 일들의 데이터를 가져온다.
혹은 weworkremotely.com 에서 데이터를 가져올수도 있다.
그리고 이 모든 데이터들을 하나의 엑셀 파일에다 정리할수 도 있다.
웹 스크래핑을 통해 여러가지 정보를 수집할 수 있는데,
예를 들어 어떤 회사에 대한 기사들을 투자 정보를 얻기 위해 여러 웹사이트에서 가져올 수 도 있으며,
같은 제품을 판매하는 여러 웹사이트의 가격들 데이터를 수집하여 제일 싸게 구매 할 수 있는 곳을 선별할 수 도 있다.
Python 과 Beautifulsoup 를 통해서 웹 스크래퍼를 제작할 수 있다.
beautifulsoup는 웹사이트의 데이터를 받아올 수 있게 해주는 python 라이브러리다.
실제로는 HTML 에서 받아온다.
HTML은 웹사이트를 만들 때 사용되는 언어이다.
웹사이트의 데이터가 HTML 언어로 작성되어 있어 HTML 언어의 기본적인 부분을 알고 시작하는 것이 좋다.
beautifulsoup 다운로드 방법
1. cmd 창을 열고
2. python -m pip install --upgrade pip
3. pip install beautifulsoup4
설치 완료 이후에
python 입력 후
>>from bs4 import BeautifulSoup
입력 시 아무런 반응 없이 >> 만 나오면 정상 설치된 것이다.
cmd창에서 pip list 또는 pip freeze 를 입력 하면 지금까지 설치했던 모듈이 나온다.
이전 게시글에서 웹사이트 상태를 가져오는 코드를 작성했기 때문에 이미 requests 를 설치했다.
request 가 설치 안되어 있다면
cmd 창 열고 pip install requests 입력하면 설치된다.
웹스크래퍼는 웹사이트에서 데이터를 추출해 낸다.
어떤 웹사이트들은 이런 작업을 좋아하지 않는다.
그래서 이상한 코드를 입력해서 인증을 하거나, 봇 방지 프로그램을 사용한다.
어떤 웹사이트들은 스크래핑 작업을 정말 싫어해서 만약 데이터를 상업적 목적으로 사용하면
고소한다는 내용의 약관이 있다.
본 내용은 교육적인 목적으로 사용하기 때문에 특히 상업적 용도로 사용할 생각이라면 이러한 사실을 잘 알고 조심해야한다.
weworkremotely 사이트를 스크래핑 해본다.
위 사이트는 웹사이트 구성이 바뀔수 있기 때문에 항상 같은 코드로 스크래핑이 불가능할수가 있다.
그러므로 변화에 맞게 코드를 수정해줘야 할 필요가 있다.
우측 상단 검색 창에 python 을 검색해본다.
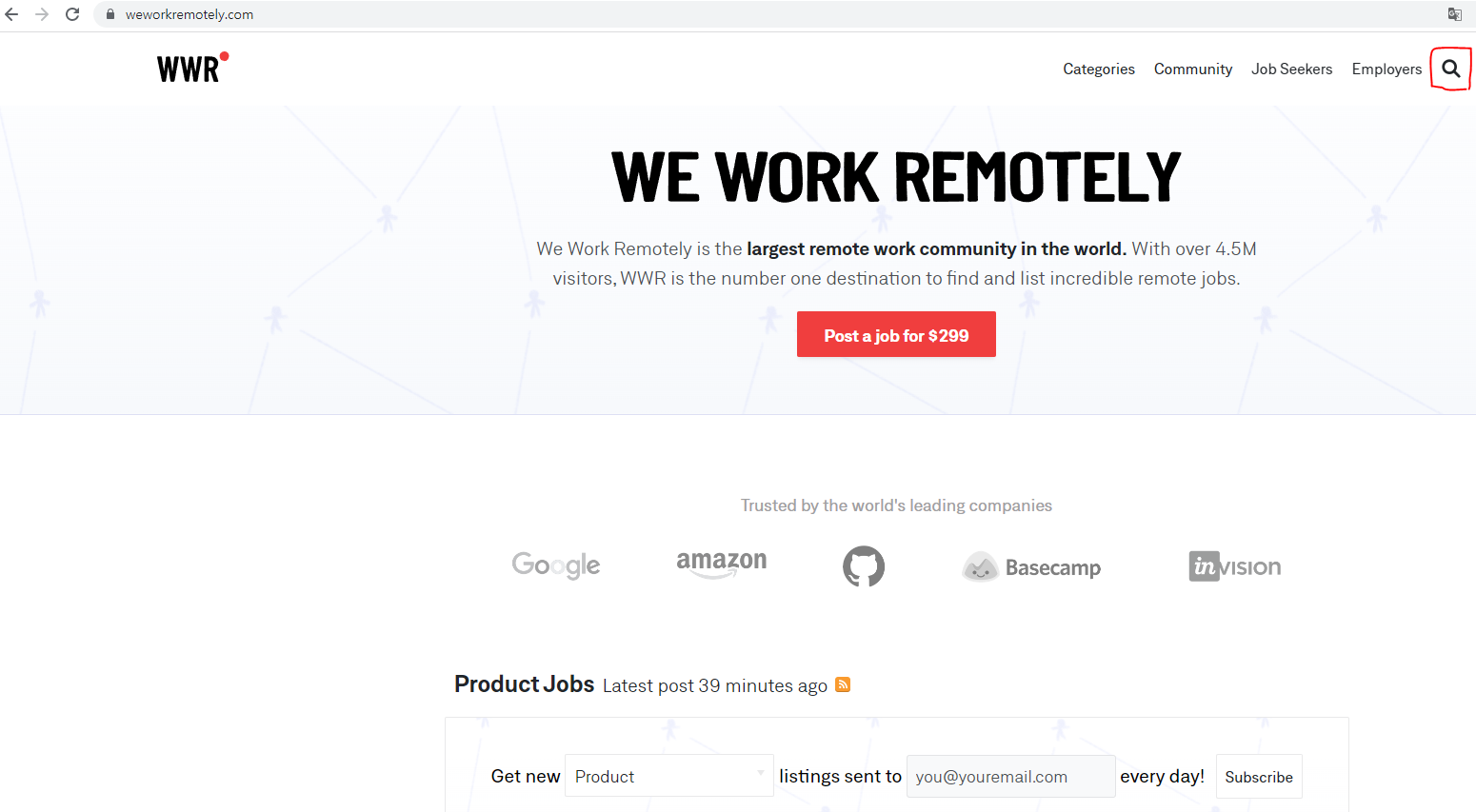
아래 화면 처럼 url 에 python 이라 입력이 되어 있는게 보인다. 이 부분에 react 라고 다시 검색을 해본다.
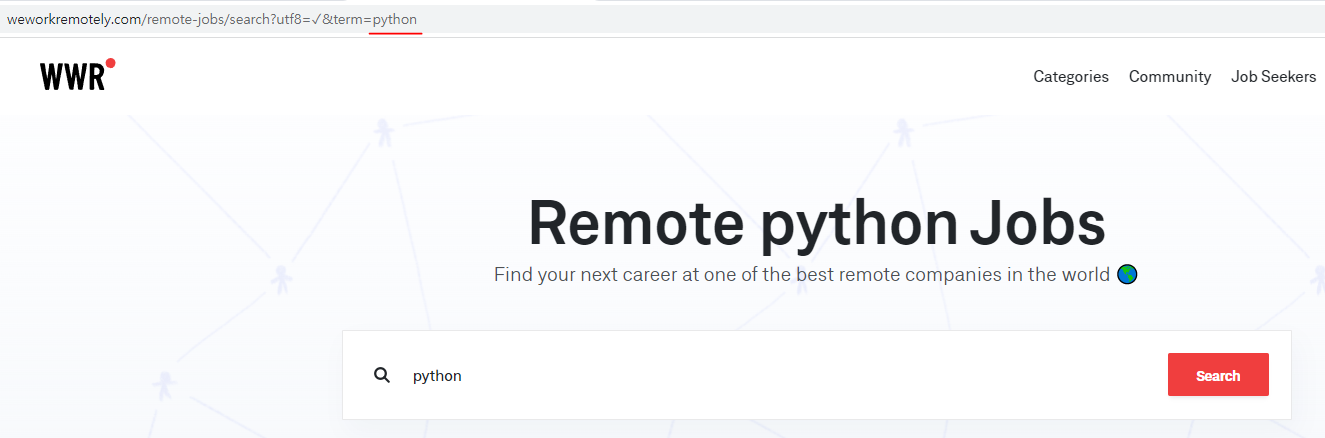
react 로 검색하면 react 로 검색한 결과 나온다. react 관련 일들이 검색 결과로 나온다.

이로써 빨간 줄이 그어진 저 url 부분이 검색창에 입력되는 키워드라는 것을 알 수 있다.
이제는 HTML 을 분석해봐야 한다. 어떤 구조로 구성되어 있는지.
화면에서 마우스 우클릭 후 inspect 를 누르거나, 검사를 누르면 HTML 코드를 확인할 수 있다.
아래 화면 처럼 우측에 HTML 코드가 뜬다거나

설정을 바꿔서 아래쪽으로 뜨게 할수 도 있다.
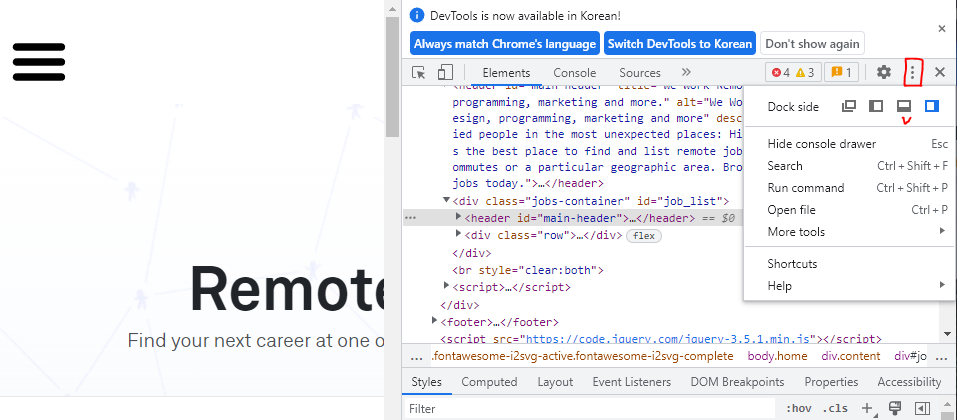
class가 job인 section을 열고 , article을 열고, ul 을 열면 li 가 여러개 있다.
li 가 사용자가 추출하려는 직업이다.
<ul> 태그는 순서가 없는 목록(undorder list)을 만들 때 사용되며,
<ul>내부에 <li>요소(list item)를 포함하여 각 항목을 표시한다.
li 중 하나를 열면 회사이름, 제목, 업무형태, 지역 등을 확인 할 수 있다.

<a href= 링크> 링크를 통해 해당 구직 공고 링크로 들어갈 수 있다.
회사이름이 OpenCraft
제목 Senior Open Source Developer & DevOps
구직형태 Full-Time/Anywhere in the World
아래 화면을 통해 여러 요소들을 확인할 수 있다.

위 사이트들의 정보를 가지고 python 으로 간단한 정보를 가져와본다.
base_url 에는 검색하면 어떠한 결과가 나오는 url 을 넣고,
search_term 에는 검색하는 키워드를 넣어준다.
response 변수에 get 메서드를 사용하여 base_url + search_term 을 합친 웹사이트를 불러온다.
status_code ( HTTP 상태코드 ) 가 200 ( 정상 ) 이 아닌 경우에는 Can't request website 를 출력,
status_code ( HTTP 상태코드 ) 가 200 ( 정상 ) 인 경우에는 text 형태로 python으로 불러온다.
from requests import get
base_url = "https://weworkremotely.com/remote-jobs/search?utf8=%E2%9C%93&term="
search_term = "python"
response = get(f'{base_url}{search_term}')
if response.status_code != 200:
print("Can't request website")
else:
print(response.text)코드가 잘 실행됬는지 확인하기 위해서,
페이지의 맨 밑에부분의 공고인 Doximity 회사의 Python Platform Engineer 부분을 검색해 본다.
실제로 잘 검색이 된다. ( Ctrl + F 로 검색 )