Python Beautifulsoup 복습
5.9 Recap
< Beautifulsoup 복습 >
Beautifulsoup를 이용하여 웹사이트의 HTML 데이터를 가져왔었다.
We Work Remotely: Remote jobs in design, programming, marketing and more
Find the most qualified people in the most unexpected places: Hire remote! We Work Remotely is the best place to find and list remote jobs that aren't restricted by commutes or a particular geographic area. Browse thousands of remote work jobs today.
weworkremotely.com
위 사이트에서 데이터를 가져왔었는데, 검색창에 무엇을 넣든 url에 나타나는것을 확인했다.

2개의 변수(variable)를 만들었다.
1개는 검색어가 없는 기본 url , → base_url
다른 1개는 계속 바뀔수 있는 검색어(키워드) 이다. → search_term
from requests import get
from bs4 import BeautifulSoup
base_url = "https://weworkremotely.com/remote-jobs/search?utf8=%E2%9C%93&term="
search_term = "python"이 2개의 변수를 합치면 1개의 전체 url이 생성이 되고,
response 를 받아서( get메서드를 사용해서 가져온다 ) , status_code 가 200인지 아닌지 확인한다.
status_code는 http 상태코드로 200 은 정상이라는 뜻이다.
( http 상태코드 관련 게시물은 여기를 클릭 )
만약 200 이 아니라면 에러를 출력하고 ( Can't request website )
base_url = "https://weworkremotely.com/remote-jobs/search?utf8=%E2%9C%93&term="
search_term = "python"
response = get(f'{base_url}{search_term}')
if response.status_code != 200:
print("Can't request website")200 이라면 웹사이트의 내용을 가지고 beautifulsoup 를 사용했다.
response.text 는 방금 얻은( response = get(f'{base_url}{search_term}' ) 웹사이트의 HTML 코드를 준다.
soup = BeautifulSoup(response.text,'html.parser') → beautifulsoup 에게 웹사이트 HTML 코드를 준다.
beautifulsoup는 내가 가진 html 코드를 다룰 수 있는 python entity로 변환해준다.
string 뿐 아니라 실제 python 데이터 구조로 이용할 수 있다.
response = get(f'{base_url}{search_term}')
if response.status_code != 200:
print("Can't request website")
else:
results =[]
soup = BeautifulSoup(response.text,'html.parser')
jobs = soup.find_all('section', class_="jobs")
내가 웹사이트의 내용으로 beautifulsoup를 호출하면,
나는 그 코드 안에서 검색을 할 수 있다.
ex) class 이름이 jobs인 모든 section 을 찾을 수 있다.

soup.find_all 을 사용해 jobs 를 얻는다. ( class 이름이 jobs 인 section )
→ string 이 아니고 python 의 데이터 구조, entity 이다.
이런 경우 jobs는 내가 찾은 모든 section의 리스트 이다.
그러므로 아래 코드처럼 for job_section in jobs 같은 for 문을 사용할 수 있다.
if response.status_code != 200:
print("Can't request website")
else:
results =[]
soup = BeautifulSoup(response.text,'html.parser')
jobs = soup.find_all('section', class_="jobs")
for job_section in jobs:
job_posts = job_section.find_all('li')
job_posts.pop(-1)beautifulsoup는 모든 것을 python의 데이터 구조로 바꿔서
내가 쓸 수 있는 entity로 만들기 때문에
나는 job section 내부를 검색할 수 있다.

beautifulsoup는 이 section들을 얻을 수 있게 해주며,
section 내부를 검색할 수 있게 해준다.
아래 코드에서는 section 내부의 모든 li 를 찾아준다.

section 으로 가서 모든 li 를 검색하고,
마지막 li 가 view-all 이라는 class 를 가지고 있는데 ( view-all 이라는 버튼 )
view-all 은 필요없는 li 이기 때문에 모든 li를 찾은 후 pop 메서드를 사용해서 view-all li 제거.
job_posts.pop(-1) → job_posts 변수의 리스트에서 마지막 li 를 제거한다.

pop은 python 리스트가 가진 메서드이며, -1로 인덱스를 설정하면 마지막에서부터 시작한다.
job_posts 리스트에서 마지막 항목을 지우게 된다. ( 마지막 li )
job_posts 는 다른 for 문을 쓸 수 있는 리스트 이다.
이 경우 아래 li 리스트 안에서 for 문을 사용한다.

첫번째로 section의 리스트를 얻고,
section들의 내부에서 모든 li의 리스트를 얻는다.
for job_section in jobs:
job_posts = job_section.find_all('li')
job_posts.pop(-1)
for post in job_posts:
anchors = post.find_all('a')
anchor = anchors[1]
link = anchor['href']
company, kind, region = anchor.find_all('span',class_='company')
title = anchor.find('span', class_='title')for job_section in jobs → class 가 jobs 인 section 에서 job_section 변수로 반복
job_posts = job_section.find_all('li') → job_section 에서 li 찾아서 job_posts 변수에 넣는다.
job_posts.pop(-1) → 마지막 view_all li 를 제거한다. ( 필요없는 li 이므로 )
for post in job_posts: → li 로 이루어진 job_posts 에서 post 변수로 반복
( post 변수는 원하는데로 이름 작성 )
html 내부를 보면 내가 원하는 데이터를 가진 anchor 를 찾을 수 있다.
anchors = post.find_all('a') → anchors 라는 변수에 a 를 찾아서 넣는다.
anchor = anchors[1] → anchor 라는 변수에 a 를 찾은 결과의 2번째 결과를 넣는다.
( 컴퓨터 0,1,2 순서 → 사람 1,2,3 순서 )
첫번째 a 는 단순 회사 소개로 필요없는 a
두번째 a 가 내가 필요한 구인 정보

link = anchor['href'] → 'href' key 의 value 를 link 변수에 넣는다. ( anchor 는 딕셔너리이다. )
( href 은 링크로 나중에 엑셀로 저장해서, 링크를 클릭해서 정보를 확인하기 위해 )
company, kind, region = anchor.find_all('span',class_='company')
→ company, kind, region 각 변수에 anchor 에서 span 의 class 가 company 인 데이터를 넣는다
( company > Optimile , company > Full-Time, region company > Europe Only )
( 첫번째 span 은 company의 이름, 두번째 span은 일의 형태, 세번재 span은 근무 지역 )
title = anchor.find('span', class_='title')
→ title 변수에 anchor 에서 찾은 span 의 class 가 title 인 데이터를 넣는다.
( find_all 안쓰고 find 쓴 이유는, find_all은 찾은 모든 것들의 리스트를 주고 find는 하나의 항목만 준다 )
company, kind, region = anchor.find_all('span',class_='company')
title = anchor.find('span', class_='title')
job_data = {
'company': company.string,
'time': kind.string,
'region': region.string,
'position': title.string
}job_data 라는 딕셔너리를 만들어서 company, time, region, postion 이라는 key에
company.string , kind.string, region.string , title.string 라는 value 를 넣는다.
( .string을 사용하면 태그 안에 있는 텍스트를 준다. )
<span class='title'>(Senior) Python Full Stack Software Developer</span> 태그와 텍스트를
(Senior) Python Full Stack Software Developer 이런 텍스트로만 준다.
job_data = {
'company': company.string,
'time': kind.string,
'region': region.string,
'position': title.string
}
results.append(job_data)
for result in results:
print(result)
print('/////////////////')results 라는 빈 리스트에 job_data 딕셔너리에서 얻은 텍스트들을 추가한다.
( results 는 for 문 밖에 만든 리스트 이다. )

첫번째 for 문은 job 에 있는 모든 section 에서 실행되고
두번째 for 문은 section 의 모든 li 에서 실행되서
만약 이 데이터를 저장하지 않으면 사라진다.
그래서 제일 밖에 results 라는 리스트를 만들고,
job_section에서 추출된 리스트에서 job 을 추출할 때 마다
job 을 results 안에 넣는다. → job 1개를 results 리스트에 추가한다.

위 2개의 for 문이 끝날 때 results 리스트 안을 확인하기 위해
results 안에 있는 result 들을 print 해서 확인한다.
< 전체코드 >
from requests import get
from bs4 import BeautifulSoup
base_url = "https://weworkremotely.com/remote-jobs/search?utf8=%E2%9C%93&term="
search_term = "python"
response = get(f'{base_url}{search_term}')
if response.status_code != 200:
print("Can't request website")
else:
results =[]
soup = BeautifulSoup(response.text,'html.parser')
jobs = soup.find_all('section', class_="jobs")
for job_section in jobs:
job_posts = job_section.find_all('li')
job_posts.pop(-1)
for post in job_posts:
anchors = post.find_all('a')
anchor = anchors[1]
link = anchor['href']
company, kind, region = anchor.find_all('span',class_='company')
title = anchor.find('span', class_='title')
job_data = {
'company': company.string,
'time': kind.string,
'region': region.string,
'position': title.string
}
results.append(job_data)
for result in results:
print(result)
print('/////////////////')< link 를 추가한 전체코드 >
from requests import get
from bs4 import BeautifulSoup
base_url = "https://weworkremotely.com/remote-jobs/search?utf8=%E2%9C%93&term="
search_term = "python"
response = get(f'{base_url}{search_term}')
if response.status_code != 200:
print("Can't request website")
else:
results =[]
soup = BeautifulSoup(response.text,'html.parser')
jobs = soup.find_all('section', class_="jobs")
for job_section in jobs:
job_posts = job_section.find_all('li')
job_posts.pop(-1)
for post in job_posts:
anchors = post.find_all('a')
anchor = anchors[1]
link = anchor['href']
company, kind, region = anchor.find_all('span',class_='company')
title = anchor.find('span', class_='title')
job_data = {
'link': link,
'company': company.string,
'time': kind.string,
'region': region.string,
'position': title.string
}
results.append(job_data)
for result in results:
print(result)
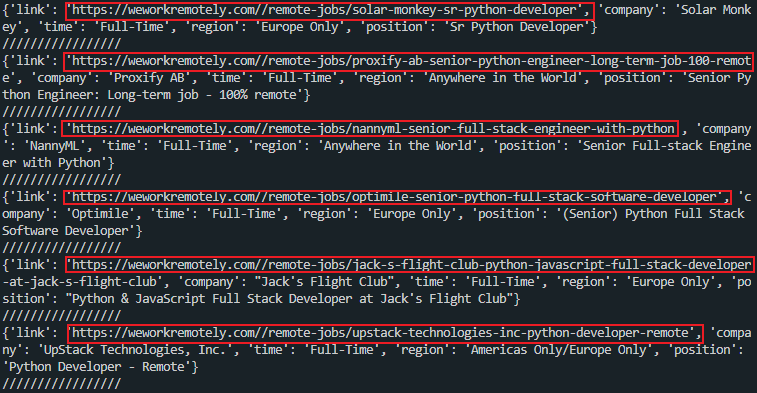
print('/////////////////')출력값:


위의 사진처럼 웹사이트의 전체 링크가 출력되는것이 아닌, 일부 링크만 출력되므로
약간의 코드수정으로 전체링크가 포함되게 출력해준다.
'link': f"https://weworkremotely.com/{link}" ,
< 웹사이트 전체 url 이 나오는 link 를 포함한 전체 코드 >
from requests import get
from bs4 import BeautifulSoup
base_url = "https://weworkremotely.com/remote-jobs/search?utf8=%E2%9C%93&term="
search_term = "python"
response = get(f'{base_url}{search_term}')
if response.status_code != 200:
print("Can't request website")
else:
results =[]
soup = BeautifulSoup(response.text,'html.parser')
jobs = soup.find_all('section', class_="jobs")
for job_section in jobs:
job_posts = job_section.find_all('li')
job_posts.pop(-1)
for post in job_posts:
anchors = post.find_all('a')
anchor = anchors[1]
link = anchor['href']
company, kind, region = anchor.find_all('span',class_='company')
title = anchor.find('span', class_='title')
job_data = {
'link': f"https://weworkremotely.com/{link}" ,
'company': company.string,
'time': kind.string,
'region': region.string,
'position': title.string
}
results.append(job_data)
for result in results:
print(result)
print('/////////////////')출력값: