
5.8 Saving Results
이전 게시물에서 weworkremotely posts 에서 href 데이터(구인정보 링크)를 추출하여
각 링크에 대한 구인 정보를 company, kind, region, job title 을 출력했다.
이전까지 진행한 코드
from requests import get
from bs4 import BeautifulSoup
base_url = "https://weworkremotely.com/remote-jobs/search?utf8=%E2%9C%93&term="
search_term = "python"
response = get(f'{base_url}{search_term}')
if response.status_code != 200:
print("Can't request website")
else:
soup = BeautifulSoup(response.text,'html.parser')
jobs = soup.find_all('section', class_="jobs")
for job_section in jobs:
job_posts = job_section.find_all('li')
job_posts.pop(-1)
for post in job_posts:
anchors = post.find_all('a')
anchor = anchors[1]
link = anchor['href']
company, kind, region = anchor.find_all('span',class_='company')
title = anchor.find('span', class_='title')
print(company, kind, region, title)
print("////////////////////////")
print("////////////////////////")
.string 이라는 method 를 사용해서
span 에서 필요한 텍스트만을 추출하려한다.
https://www.crummy.com/software/BeautifulSoup/bs4/doc/#string
Beautiful Soup Documentation — Beautiful Soup 4.9.0 documentation
Non-pretty printing If you just want a string, with no fancy formatting, you can call str() on a BeautifulSoup object, or on a Tag within it: str(soup) # ' I linked to example.com ' str(soup.a) # ' I linked to example.com ' The str() function returns a str
www.crummy.com
company.string
kind.string
region.string
title.string 사용
from requests import get
from bs4 import BeautifulSoup
base_url = "https://weworkremotely.com/remote-jobs/search?utf8=%E2%9C%93&term="
search_term = "python"
response = get(f'{base_url}{search_term}')
if response.status_code != 200:
print("Can't request website")
else:
soup = BeautifulSoup(response.text,'html.parser')
jobs = soup.find_all('section', class_="jobs")
for job_section in jobs:
job_posts = job_section.find_all('li')
job_posts.pop(-1)
for post in job_posts:
anchors = post.find_all('a')
anchor = anchors[1]
link = anchor['href']
company, kind, region = anchor.find_all('span',class_='company')
title = anchor.find('span', class_='title')
print(company.string, kind.string, region.string, title.string)
print("////////////////////////")
print("////////////////////////")출력값:
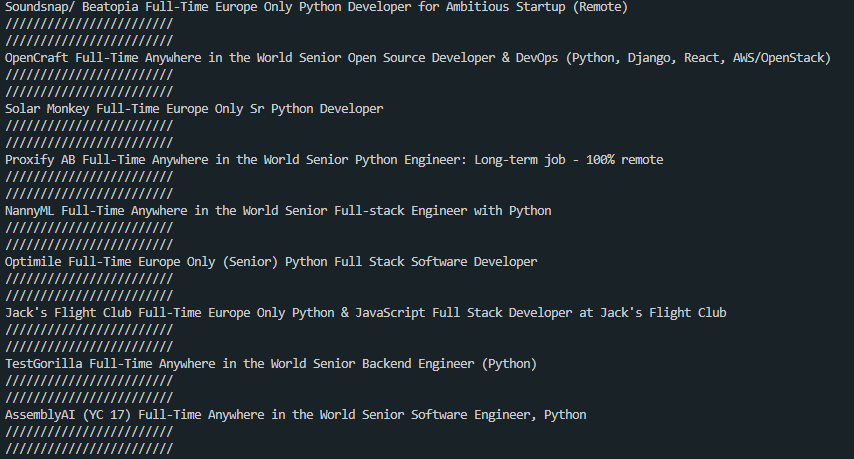
데이터를 저장하기 위해 job_data 라는 dictionary를 만든다.
company.string
kind.string
region.string
title.string
각 string 에 맞는 key 와 value 를 만든다.
'company' : company.string
'time' : kind.string
'region' : region.string
'title' : title.string
페이지의 각 section에서 재생성되는 리스트 안의 각 post 때문에
for 문이 반복되는 동안 job_data 딕셔너리는 계속 재생성되므로,
for 문 밖에서 출력하게 한다.
result 라는 새로운 빈 리스트를 만들어서, job_data를 추출할때마다
append 메서드를 사용해서 result 리스트에 추가해준다.
from requests import get
from bs4 import BeautifulSoup
base_url = "https://weworkremotely.com/remote-jobs/search?utf8=%E2%9C%93&term="
search_term = "python"
response = get(f'{base_url}{search_term}')
if response.status_code != 200:
print("Can't request website")
else:
result =[]
soup = BeautifulSoup(response.text,'html.parser')
jobs = soup.find_all('section', class_="jobs")
for job_section in jobs:
job_posts = job_section.find_all('li')
job_posts.pop(-1)
for post in job_posts:
anchors = post.find_all('a')
anchor = anchors[1]
link = anchor['href']
company, kind, region = anchor.find_all('span',class_='company')
title = anchor.find('span', class_='title')
job_data = {
'company': company.string,
'time': kind.string,
'region': region.string,
'position': title.string
}
result.append(job_data)
print(result)출력값:

딕셔너리로 이루어진 job_data 리스트를 추출했다.
for 문을 한번 더 사용해서 구분자와 함께 출력해본다.
기존의 result 리스트를 results 로 변경 후
for result in results 로 for문 작성
from requests import get
from bs4 import BeautifulSoup
base_url = "https://weworkremotely.com/remote-jobs/search?utf8=%E2%9C%93&term="
search_term = "python"
response = get(f'{base_url}{search_term}')
if response.status_code != 200:
print("Can't request website")
else:
results =[]
soup = BeautifulSoup(response.text,'html.parser')
jobs = soup.find_all('section', class_="jobs")
for job_section in jobs:
job_posts = job_section.find_all('li')
job_posts.pop(-1)
for post in job_posts:
anchors = post.find_all('a')
anchor = anchors[1]
link = anchor['href']
company, kind, region = anchor.find_all('span',class_='company')
title = anchor.find('span', class_='title')
job_data = {
'company': company.string,
'time': kind.string,
'region': region.string,
'position': title.string
}
results.append(job_data)
for result in results:
print(result)
print('/////////////////')출력값:
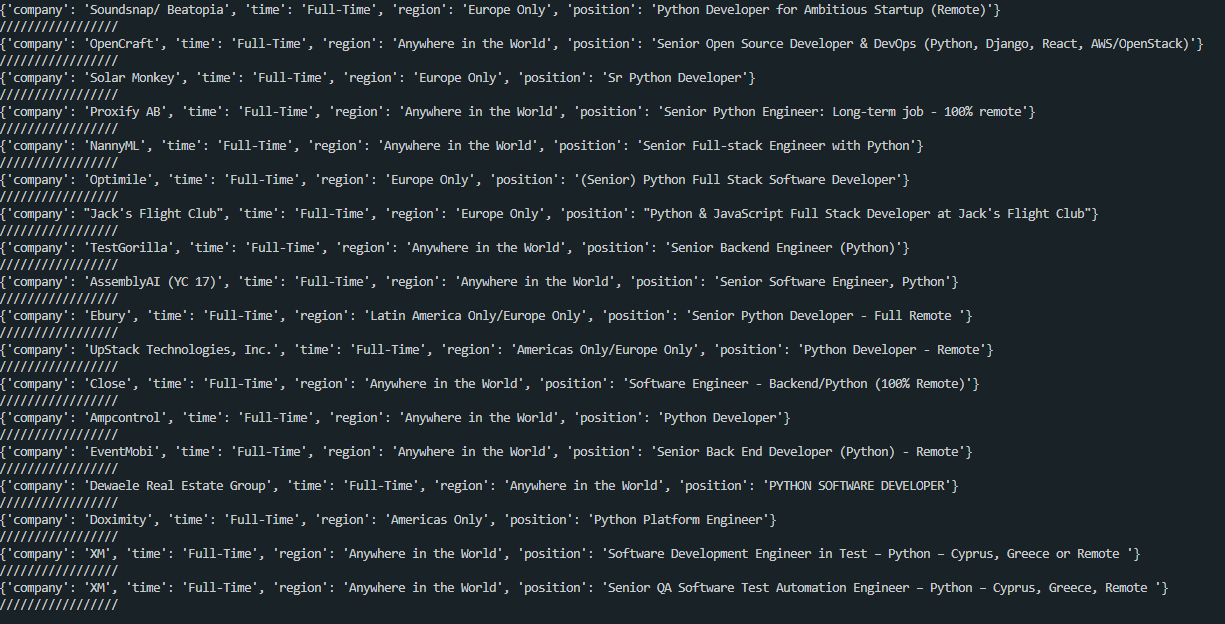
코드가 정상적인지 확인하기 위해 python 검색어 말고 react.js 검색어로 입력한 결과를 출력해본다.
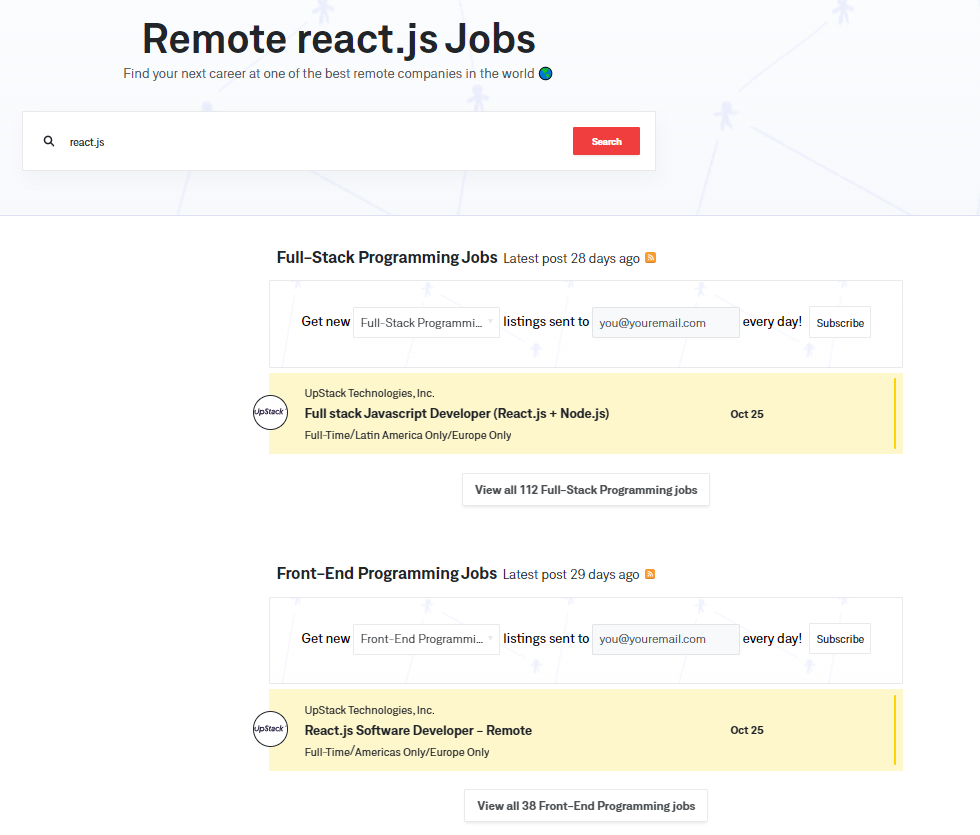
search_term 변수에 react.js 를 넣어준다.
from requests import get
from bs4 import BeautifulSoup
base_url = "https://weworkremotely.com/remote-jobs/search?utf8=%E2%9C%93&term="
search_term = "react.js"
response = get(f'{base_url}{search_term}')
if response.status_code != 200:
print("Can't request website")
else:
results =[]
soup = BeautifulSoup(response.text,'html.parser')
jobs = soup.find_all('section', class_="jobs")
for job_section in jobs:
job_posts = job_section.find_all('li')
job_posts.pop(-1)
for post in job_posts:
anchors = post.find_all('a')
anchor = anchors[1]
link = anchor['href']
company, kind, region = anchor.find_all('span',class_='company')
title = anchor.find('span', class_='title')
job_data = {
'company': company.string,
'time': kind.string,
'region': region.string,
'position': title.string
}
results.append(job_data)
for result in results:
print(result)
print('/////////////////')출력값:

2개의 결과가 똑같이 출력된다.
'Programming > Python 웹 스크래퍼 만들기' 카테고리의 다른 글
| Python Refactor (0) | 2022.11.25 |
|---|---|
| Python Beautifulsoup 복습 (0) | 2022.11.24 |
| Python Job Extraction (0) | 2022.11.22 |
| Python Job Posts (1) | 2022.11.21 |
| Python Keyword Arguments (0) | 2022.11.18 |